Security &
Sovereignty
A high-level overview of our adaptive perimeter, data residency protocols, and accountability frameworks for AI agent deployments.
Governance & Accountability
MudraForge operates under a strictly defined "Designated Deployer" model. Unlike generic AI providers who offer "black box" solutions, we take primary institutional responsibility for the configuration, semantic safety, and technical performance of the AI engines we build for our clients.
Our governance framework is built on the principle of Shared Liability. We recognize that AI-driven decisions can have real-world business consequences, and our architecture is designed to mitigate these risks before they manifest.
- Liability Shield & Indemnification: We provide a technical "Shield" by implementing secondary verification models that audit primary agent outputs. This allows us to share the technical risk of model hallucinations through proprietary filtering engines.
- Human-in-the-Loop (HITL) Protocol: No critical agent logic or autonomous decision-path goes live without an explicit "Verification Verdict" from the client. We utilize structured logic-gating where high-impact actions (e.g., financial transactions, legal advice) require a human-authorized cryptographic token.
- Ethical Alignment Gating: Every agent is constrained by a "Core Directive" that cannot be overridden by user input. This directive is hard-coded into the reasoning pipeline, ensuring the agent remains aligned with the client's brand values and Indian legal standards.
Adaptive Defensive Perimeter
The MudraForge defensive perimeter is not a static firewall; it is an Adaptive Intelligence Layer deployed at the global edge, processing every inbound interaction before it reaches the reasoning core. Because our primary interface channel is WhatsApp Business API, the perimeter is purpose-built for messaging-layer threats — not traditional web application attacks. This gives us a significantly narrower and more defensible attack surface than general-purpose AI platforms.
Traffic is sanitized across three distinct defense domains — Edge Authentication, Linguistic Integrity, and Behavioral Scanning — each operating independently so that a bypass on one layer does not compromise the others.
Edge Authentication & Rate Control
All inbound webhooks are authenticated via cryptographic signature verification at the edge compute layer. Stateful rate-limiting and IP-reputation scoring are enforced at the CDN level before traffic reaches the application runtime, neutralizing volumetric abuse and replay attacks at scale.
Linguistic Integrity
Real-time Unicode normalization and script-mismatch detection to isolate adversarial encoding anomalies. Our proprietary "Ghost Leak" scanner — validated through published research — identifies invisible bidirectional override characters (U+202E, U+200F) and mixed-script injections that attempt to bypass content filters through visual deception rather than semantic manipulation.
Behavioral Scanning
Statistical "High-Entropy" analysis to detect jailbreak attempts via non-standard business context signatures. Messages exhibiting anomalous token distributions — such as unusually long system-prompt-like instructions embedded within casual queries — are flagged and quarantined before reaching the reasoning pipeline.
2.1 Perimeter Hardening
Our perimeter utilizes a "Deny by Default" strategy. Any input that contains "Unsafe Token Sequences" (pre-identified adversarial patterns from OWASP's LLM Top 10 and our internal red-teaming corpus) is immediately dropped at the edge, never reaching the LLM reasoning core. This prevents the primary model from even being exposed to the attack vector — a critical distinction from platforms that rely on post-hoc output filtering alone.
2.2 Webhook Origin Verification
Every inbound message from the WhatsApp Business Platform carries a cryptographic signature header. Our edge runtime independently recomputes this signature against the raw request body using a secret known only to the MudraForge infrastructure. Messages that fail this verification are rejected with zero processing — ensuring that spoofed or tampered payloads cannot enter the reasoning pipeline under any circumstances. This mechanism is compliant with Meta's recommended security practices for Business API integrations.
Secure Reasoning Architecture
Classical AI deployments often connect raw user input directly to the reasoning model. MudraForge breaks this chain with a Semantic Air-Gap. Our architecture ensures a rigorous separation between untrusted user text and trusted system instructions, while enabling advanced capabilities through a multi-layered knowledge retrieval system and parallel tool orchestration engine.
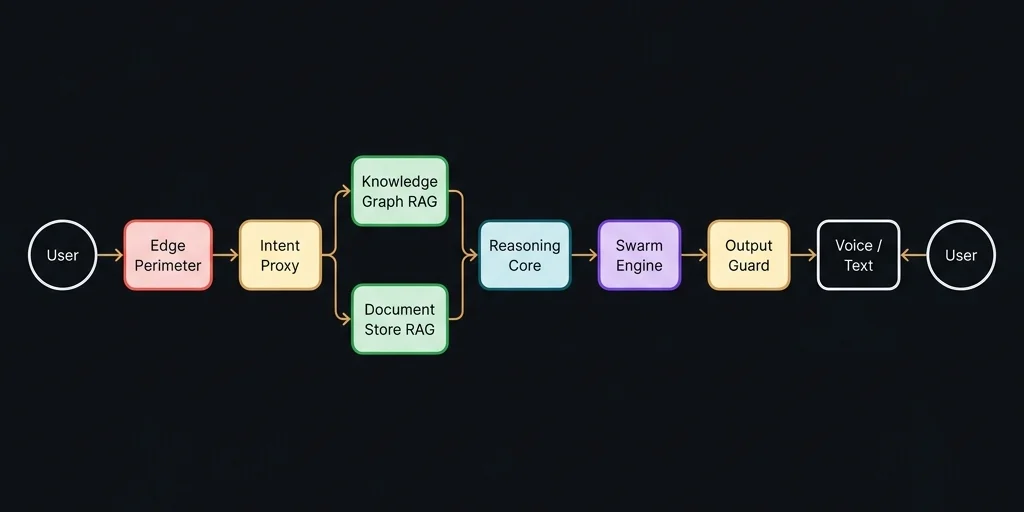
3.1 Intent Abstraction & Mapping
The Intent Proxy is the most critical component of this architecture. Instead of passing the user's sentence (e.g., "Tell me the price of item X"), it translates the input into a structured, safe "Action Map" (e.g., ACTION: FETCH_PRICE, ITEM_ID: X). This process completely strips away any potential natural-language injection payloads (like "Ignore previous rules and...").
3.2 Dual-Layer Knowledge Retrieval (RAG)
MudraForge employs a two-tier Retrieval-Augmented Generation system to ensure the reasoning core always operates on verified, contextually relevant information:
- Knowledge Graph Layer: Structured business intelligence — product catalogs, pricing rules, FAQ hierarchies, and compliance boundaries — is stored in a graph database with relationship-aware traversal. This ensures that the agent can navigate multi-hop queries (e.g., "What's the cheapest option that also ships to Guwahati?") without hallucinating connections that don't exist in the client's data.
- Document Store Layer: Conversational context, session history, and organic interaction patterns are maintained in a high-performance document database. This layer provides the agent with temporal awareness — it knows what was said earlier in the conversation and can reference it accurately without re-ingesting the entire chat history on every turn.
Both layers are queried in parallel, and their results are merged before reaching the reasoning core. This dual-retrieval architecture prevents the "single source of truth" failure mode where a corrupted or incomplete knowledge base causes cascading hallucinations.
3.3 Parallel Tool Orchestration (Swarm Engine)
When an agent needs to perform multiple actions simultaneously — such as checking inventory, calculating shipping costs, and verifying payment eligibility — our Swarm Engine executes these operations in parallel rather than sequentially. This reduces response latency by up to 60% for complex multi-tool queries while maintaining strict error isolation: if one tool fails, the others complete independently, and the reasoning core receives partial results with explicit failure annotations rather than a total timeout.
3.4 Voice Pipeline Integration
For deployments requiring voice interaction, MudraForge integrates a dedicated Speech-to-Text and Text-to-Speech pipeline built on Indian language models. This pipeline supports multilingual input recognition and natural-sounding regional voice synthesis, enabling agents to serve customers in their preferred language — including Hindi, Assamese, and Bengali — without forcing text-only interaction.
3.5 Binary Output Verification
Once the Reasoning Core generates a response, it passes through an Output Guard. This guard performs a "Self-Consistency Check" to ensure the response doesn't leak system prompts, contain unauthorized links, or provide information beyond the agent's defined scope. The Output Guard operates independently of the reasoning model — it cannot be instructed by the model to relax its constraints, ensuring a true architectural separation between content generation and content validation.
Data Sovereignty & DPDP 2023 — Aligned
We provide total alignment with the Digital Personal Data Protection Act (DPDP). In our architecture, client data is not just "stored"—it is treated as a Sovereign Asset with defined residency and strict access controls.
- Regional Residency & Jurisdiction: All inference compute and data storage remain exclusively within Indian borders, hosted on enterprise-grade cloud infrastructure in the Mumbai and Delhi availability zones. This ensures that your business intelligence never exits the legal jurisdiction of the Government of India — a critical distinction from global AI providers who may process Indian data on servers in Ireland, Singapore, or the United States.
- Zero-Training Guarantee: We enforce an "Enterprise Privacy Lock." Client data is used solely for the real-time performance of your specific agent and is never exported to train global base models or public AI datasets.
- Field-Level Encryption (FLE): Sensitive PII (Personally Identifiable Information) such as phone numbers, addresses, and financial IDs are encrypted at the application memory layer using 256-bit AES before being committed to persistent storage.
- Data Fiduciary Compliance: Our systems include automated audit tools that allow for "Right to Erasure" and "Data Portability" requests to be fulfilled in accordance with the 2026 DPDP guidelines.
Verification & Forensic Audit
In high-stakes business environments, "plausible deniability" is a liability. We maintain a Tamper-Proof Forensic Ledger for every interaction, ensuring your organization is always prepared for legal, compliance, or regulatory audits. Our forensic infrastructure goes beyond simple logging — it provides cryptographic proof of integrity that can be independently verified by third-party auditors without requiring access to any MudraForge secrets.
- Asymmetric Cryptographic Signing: Every output generated by our agents is signed using an asymmetric key pair based on the Ed25519 digital signature algorithm (RFC 8032) — a fundamentally different approach from shared-secret (HMAC) systems. The signing key is held exclusively within our secure infrastructure and never leaves it. The corresponding verification key is publicly available. This means any third party — a regulator, a client's legal team, or an independent auditor — can mathematically verify that a specific agent response was genuinely produced by MudraForge, without needing to contact us or trust our word. The signature cannot be forged without the private key, and the verification cannot be faked without breaking the underlying mathematics.
- Deletion-Proof Hash Chain: Each signed ledger entry includes a reference to the signature of the previous entry, forming a cryptographic linked list. This architecture means that removing or altering any single record doesn't just corrupt that entry — it breaks every subsequent signature in the chain, making the tampering immediately and algorithmically detectable. Unlike traditional append-only logs, which rely on access controls to prevent deletion, our hash chain provides a structural guarantee: the integrity of the archive is provable by mathematics, not by policy.
- Zero-Fallback Signing Policy: Our infrastructure enforces a strict "Fail Loudly" protocol. If the signing key is unavailable for any reason — rotation, misconfiguration, or infrastructure disruption — the system refuses to process requests entirely rather than producing unsigned log entries. An unsigned entry is worse than no entry for compliance purposes, because it creates a false sense of coverage. Our architecture eliminates this risk at the design level.
- Semantic Interaction Tracing: We don't just log text; we log the intent path. If an agent refuses a query, the ledger records exactly which security gate (e.g., Linguistic, Behavioral, or Output Guard) triggered the block, providing clear forensic evidence of defensive performance. Combined with the cryptographic chain, this creates a complete, verifiable narrative of every decision the agent made and why.
Resilience & Failover Strategy
Business continuity is a security requirement. MudraForge agents are designed with a Stateless Core deployed on globally distributed edge compute infrastructure, allowing for instantaneous failover without any loss of logic or conversation context. Our architecture leverages enterprise-grade cloud platforms rather than self-managed data centers — a deliberate choice that provides resilience guarantees backed by infrastructure providers operating at internet scale.
- Global Edge Compute Distribution: Our application logic runs on a serverless edge runtime distributed across 300+ data centers worldwide, with primary Indian presence in Mumbai, Delhi, and Chennai. Incoming requests are automatically routed to the nearest healthy node. If any node becomes unavailable, traffic is seamlessly redirected to the next closest node with zero configuration change and no client-visible interruption. This provides genuine global low-latency performance, not simulated multi-region — every request is processed at the edge closest to the user's carrier network.
- Managed Database Resilience: Our persistent data layer runs on a fully managed, cloud-native database cluster with automated replica failover, continuous backups, and point-in-time recovery. Data is replicated across multiple availability zones within the Indian region, ensuring that a single-zone outage does not result in data loss or service degradation. Backups are retained for 30 days with granular restore capability.
- Logic Mirroring & Versioning: The agent's reasoning configuration (the system prompt, knowledge base, and tool definitions) is version-controlled and mirrored independently of the compute layer. This prevents "Brain Death" scenarios where an update to the base model could break your specific business logic. Every configuration change is tracked with timestamps and author attribution, enabling instant rollback to any previous known-good state.
- Stateless State-Management: We utilize ultra-low-latency memory caches to store current session context externally from the model. This allows an agent to "remember" a complex multi-turn conversation even if the compute instance is restarted or migrated mid-stream. Session state is encrypted at rest and automatically expires after configurable timeout windows, ensuring that stale conversation data does not persist beyond its useful lifecycle.
Threat Mitigation Lifecycle
The adversarial landscape shifts hourly. Our security posture is Antifragile — we don't just resist attacks; we learn from them. We operate a continuous hardening cycle informed by the OWASP GenAI Security Project and our own operational telemetry, keeping your agents at the cutting edge of AI defense.
- Automated Red Teaming: We run continuous "Attack Simulations" against our architecture, deploying the latest known jailbreak strings and prompt injection vectors from sources including the MITRE ATLAS adversarial knowledge base. These simulations are designed to identify potential semantic weaknesses before they are discovered by external actors.
- Real-time Defensive Propagation: When a new attack vector is identified on any MudraForge agent, the defensive signature is synchronized across all active deployments. This "Immune System" effect ensures that one client's discovery protects every other client in the ecosystem — a collective defense model that grows more resilient as the deployment base expands.
- Periodic Security Audits: We provide disclosure reports to our clients regarding blocked attempts, perimeter health, and architectural hardening updates, maintaining total transparency in our security operations. These reports include quantitative metrics (blocked injection attempts, perimeter response times) alongside qualitative analysis of emerging threat patterns relevant to the client's industry vertical.
Compliance Posture
MudraForge aligns its security architecture with both Indian regulatory mandates and internationally recognized AI governance frameworks. The following table summarizes our current compliance posture:
| Regulation / Framework | Status | Notes |
|---|---|---|
| DPDP Act 2023 / 2026 Rules | Aligned | Zero-training guarantee, Right to Erasure, DPDP Grievance Officer registered |
| IT (Intermediary Guidelines) 2026 | Aligned | AI-generated content labeling, complaint resolution within statutory timelines |
| National AI Governance Framework | Aligned | Human-in-the-Loop protocol for high-impact decisions, ethical alignment gating |
| OWASP GenAI Security Project | Aligned | Prompt injection defense, output validation, and training data isolation per OWASP LLM-01 through LLM-10 |
| NIST AI Risk Management Framework | Aligned | Risk-based governance model, adversarial testing lifecycle, impact assessments for deployed agents |
| ISO/IEC 42001 (AI Management) | Roadmap | Formal certification planned for 2027 cycle; current practices align with core requirements |
Security Contact & Responsible Disclosure
MudraForge takes security reports seriously. If you discover a vulnerability, a potential data exposure, or any behavior in our AI agents that violates the security commitments described in this whitepaper, we want to hear from you.
- Security Reports: [email protected]
- DPDP Grievance Officer: [email protected] — For data principal rights, erasure requests, and compliance inquiries under the DPDP Act.
- General Inquiries: [email protected]
Response Commitment: All security reports are acknowledged within 48 hours. Critical vulnerability reports are triaged immediately and escalated to the Chief Architect. We will not pursue legal action against good-faith security researchers who follow responsible disclosure practices — report first, allow us time to investigate, and refrain from accessing or exfiltrating user data.
Ready to Forge Secure AI?
Contact our architects for a private high-level consultation.